About The Decoder SDK
The Decoder SDK uses the Google v8 JavaScript engine. It uses the vu8 system for binding C++ to JavaScript and vice versa. This can also be leveraged by SDK users to write portions of decoders in C++.
The Decoder SDK is sometimes referred to in this and subsequent sections as the Script Decoder. These terms can be used interchangeably.
API reference
Read the Decoder SDK reference here.
Using the Decoder SDK
Your first script
A single Decoder SDK script (which we refer to as a script) is capable of operating on multiple decoders. A decoder relates to the TCP or UDP data of a single probe whereas a script relates to the entire Protocol being decoded.
This means that a single script is capable of decoding multiple TCP streams. Memory and JavaScript variables are shared in a single script. This allows decoders of a single protocol to interact with each other if desired. It is, of course, possible to store memory per Decoder also, which we explain further below.
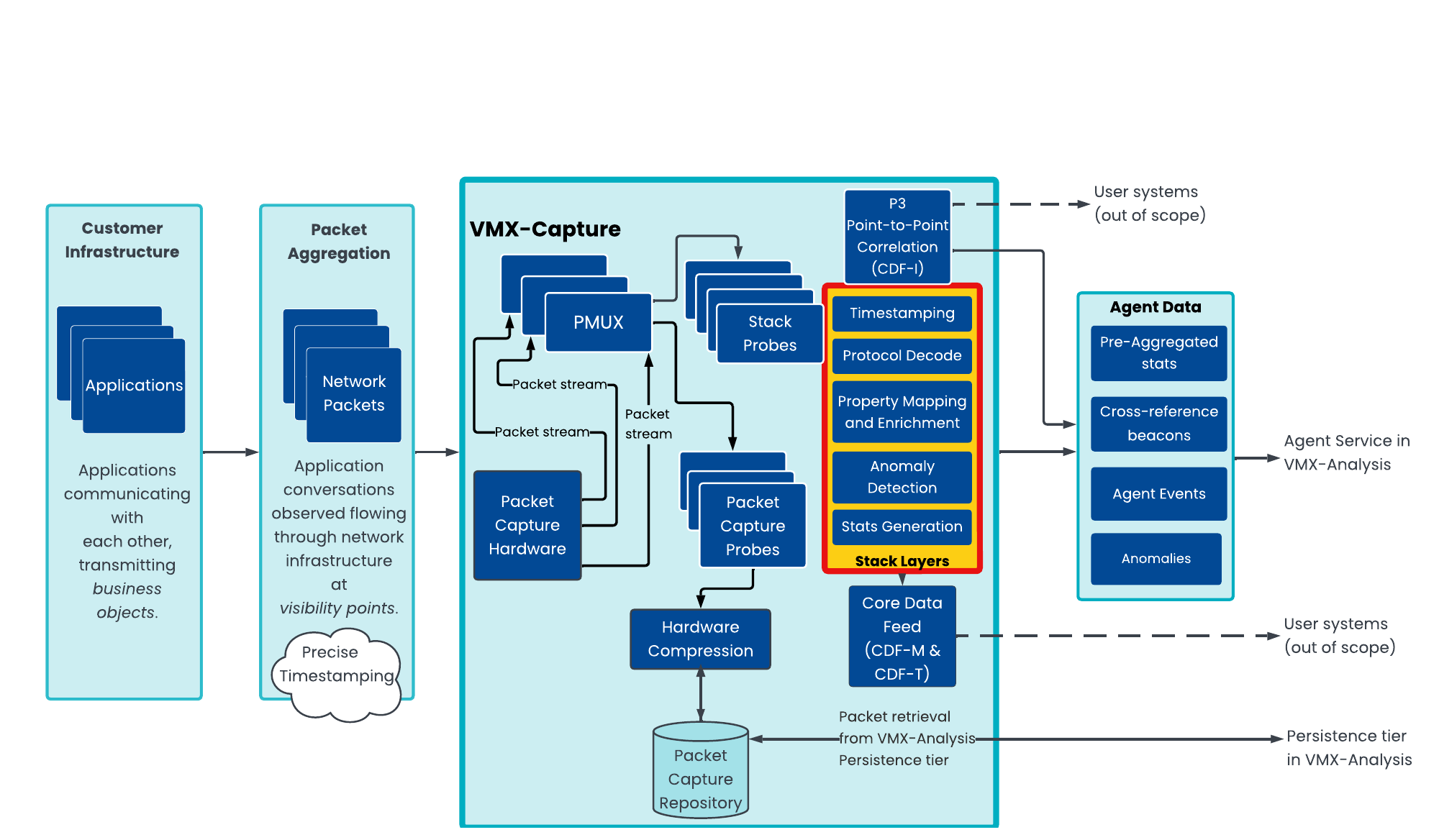
See the Configuration Guide for VMX-Capture for more information about probes, stacks, and the overall VMX-Capture architecture.
A script is loaded by the Protocol once when the script_v8 protocol is enabled and started in the UI. At this stage, the configured script is executed by the v8 JavaScript virtual machine.
var console = vu8.load('console')console.log("hello world")function on_data(dec) {}function on_new_decoder(dec) {}function on_missed_data(dec, size) {}The above script is included here for illustration purposes only and will only cause "hello world" to be logged to the VMX-Capture logs, but it demonstrates that a script body runs only once and shows how to log information from a script to the system logs.
The three functions above must be defined in every script. They constitute the callback mechanism by which the underlying VMX-Capture stack communicates with the script. We further explain this below.
The vu8.load function makes it possible to import C++ methods from shared libraries into JavaScript. It returns a handle to the library which can be used from JavaScript as a reference to call C++ methods. This can be used for advanced functionality but in most scripts it will be used purely as a way of logging information from the script. The current C++ libraries supplied for use by the Decoder SDK are documented on the vu8 page and include libraries for file IO and console logging. It also shows how to produce and load custom C++ libraries. These may be used for performance critical sections of the code allowing script decoders to break free from the confines of the v8 JavaScript virtual machine.
It can be assumed from here that all code examples have loaded the console library and assigned it to the variable console.
Creating Datafields
Datafields are a way of passing named information of various types through the stack or to a Collector.
Datafields can be interrogated and modified by other decoders. For example a stack may consist of two script v8 Protocol layers: in the first, the decoders create several Datafields and in the second, the decoders may filter or modify them according to predetermined rules.
Datafields can be passed to a Collector e.g. for passive latency analysis.
The following example shows how to create a Datafield of each type available:
var dfMarketId = new decoder.DatafieldUInt("script_v8.market_id"), dfSequence = new decoder.DatafieldInt("script_v8.sequence"), dfSymbolTicker = new decoder.DatafieldString("script_v8.symbol_ticker"), dfPrice = new decoder.DatafieldFloat("script_v8.price"), dfIsAsk = new decoder.DatafieldBool("script_v8.is_ask"), dfIPAddr = new decoder.DatafieldIPAddr("script_v8.ip_addr"), dfIPPort = new decoder.DatafieldIPPort("script_v8.ip_port")A brief introduction to the VMX-Capture stack
A VMX-Capture stack consists of a collection of one or more Protocol layers. Each stack entry usually relates to the decoding of a single internet protocol.
Each Protocol in the stack is ordered consecutively and may consist of one or more decoders. Each decoder is then capable of:
Manipulating Datafields and Statistics.
Signalling a decoder in the next Protocol stack layer to run, optionally passing it data. This data may be a portion of the data passed to the decoder, the full data passed to the decoder, or new data generated by a decoder.
Triggering a Datafield/Statistic collection by a "Collector". Only the last Protocol in a stack will directly trigger Collectors to run.
Multiple script decoders may be used in the same stack. It is also possible to layer a script decoder after a pre-existing VMX-Capture stack to further manipulate Datafields or to pre-process data before passing it on to another VMX-Capture stack Protocol.
Using the Decoder SDK is a great way of gaining an understanding of the operation of the entire VMX-Capture stack, and of how the different stack layers can interact with each other to produce incredibly flexible analytics. The Configuration Guide for VMX-Capture explains the VMX-Capture stack with more context about how it interacts with the rest of the Beeks Analytics Architecture.
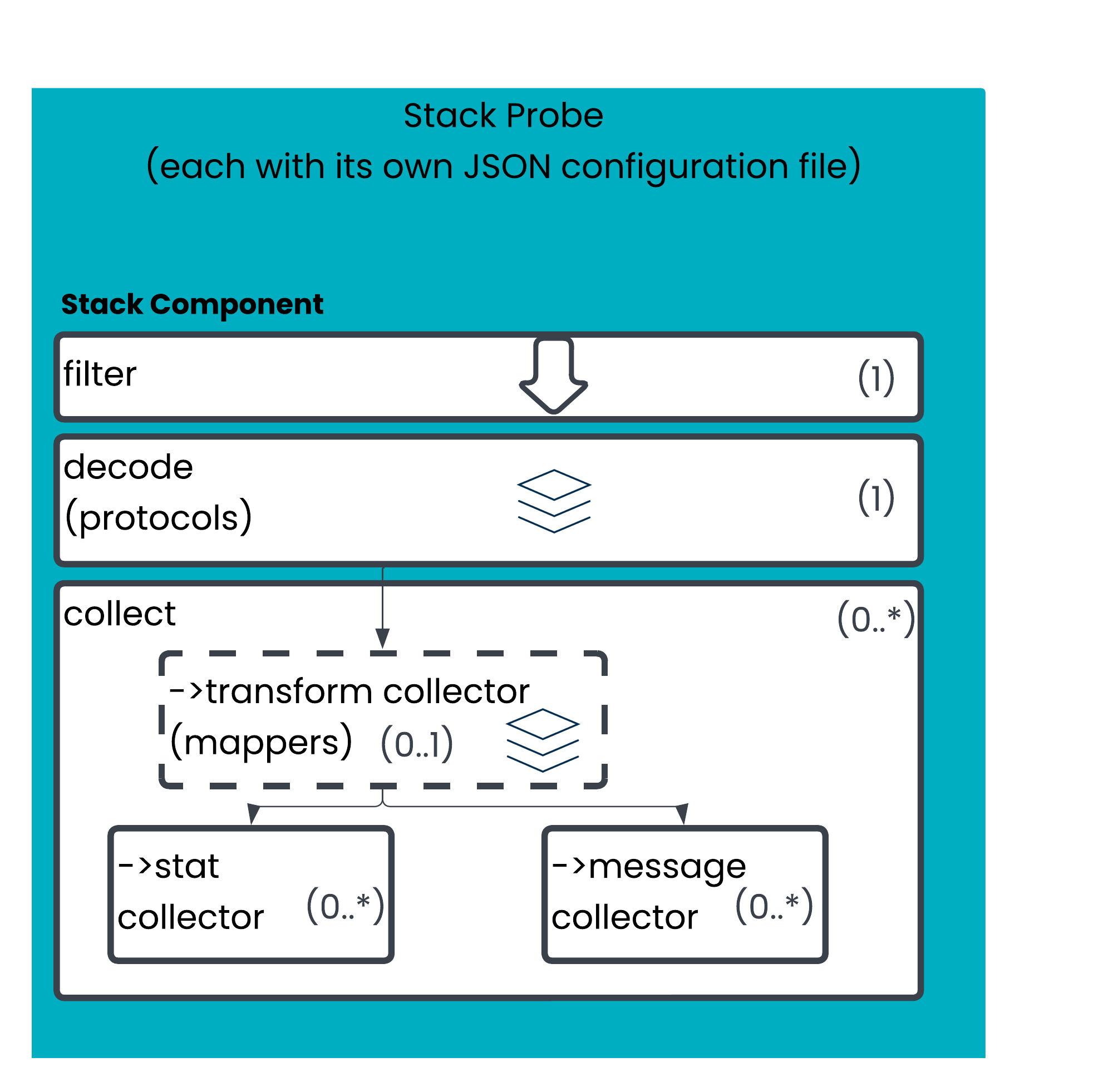
Retrieving Datafields from other layers
A script decoder may access Datafields defined in a decoder further down the VMX-Capture stack. Such Datafields may then be modified further before triggering the Collector or may be used to inform the decoding algorithm. The following code sample shows how to retrieve a Datafield from a previous stack layer and shows how to ensure the Datafield exists and is of the expected type:
var dfMarketId = decoder.protocol.getDatafield('script_v8.market_id')if (! dfMarketId) throw new Error('script_v8.market_id not found')else if (! (dfMarketId instanceof decoder.DatafieldUInt)) throw new Error('unexpected data type of script_v8.market_id')function on_data(dec) { if (! dfMarketId.isSet()) throw new Error('data field was not set by previous layer')}Note that instanceof is a built in JavaScript operator for testing that a variable conforms to a given type. When getDatafield cannot find the named datafield it returns the JavaScript null value which evaluates to false in a boolean context.
Please note that decoder.protocol.getDatafield may only be called from the main script body and not from a callback as it must be run at the time of Protocol creation. Any uncaught exceptions thrown in the main body of the script will terminate initialization of the Protocol with a log message. Uncaught exceptions within callbacks are logged together with location at which the exception was thrown.
The on_new_decoder callback and storing per-Decoder data
As mentioned before a single script may be responsible for more than one decoder of a protocol. For example the Protocol layer below it may be responsible for multiple internet protocol streams. Each decoder in a former layer will cause the creation of a companion decoder in the succeeding layer to which it may pass Datafields, Statistics, and/or data.
The on_new_decoder callback is run from the VMX-Capture Stack once for each required decoder.
This method is passed a single argument which relates to the created decoder. This object allows multiple decoders to be shared by a single script. When each decoder is passed new data, the on_data callback described in the next section will be passed the corresponding script dec object.
JavaScript is a prototypical language and new fields can be created on an object simply by assigning a value to them. This means that information relating to a single decoder can be stored within the dec object for reading by further on_data callbacks. The following example shows how to do this:
var idx = 0function on_new_decoder(dec) { dec._foundMessageBegin = false // state variable dec._idx = ++idx // assign an index to differentiate this decoder. // functions can be assigned to objects. dec._log = function(arg) { console.log("decoder " + dec._idx + " logs: " + data) }}Note that the dec object also contains some methods provided by the Decoder SDK so it is advisable to prefix custom attributes with an underscore to ensure built-in methods are not overridden; although method overriding may be useful in some circumstances and is possible.
The on_data callback and triggering a collection of Datafields
The on_data callback of a script is called in the following circumstances:
The script represents the first Protocol layer in a VMX-Capture stack and new data is available from a probe.
The script represents a subsequent Protocol layer and a previous Protocol has signalled it.
The following example shows an on_data callback that does nothing but signal the corresponding decoder from the next Protocol layer to run via the dec.nextDecoder method. It also demonstrates access to dec fields defined in the previous on_new_decoder function:
function on_data(dec) { dec._log("received new data") // call _log method defined in on_new_decoder. dec.nextDecoder() // signal the corresponding decoder in the next layer to run.}Modifying Datafields from the on_data callback
It can usually be assumed that Datafields defined by previous layers only change between on_data calls so the on_data callback is an ideal place to modify Datafields defined in previous layers:
var dfMarketId = decoder.protocol.getDatafield('script_v8.market_id')function on_data(dec) { dfMarketId.incrementBy(1) dec.nextDecoder()}If the nextDecoder is called from a script in final Protocol layer (or transitively via decoders in subsequent Protocol layers), the Collectors are triggered. This has the side effect of resetting all Datafields back to their default values.
Generating statistics using Statistic objects
A Statistic is internally stored as an IEEE double-precision floating point number and is very similar to a DatafieldFloat but is used for storing statistical data related to the underlying data stream or the work the script is doing. Statistics are only collected by the Statistic Collector.
To create a Statistic object:
var stat = new Statistic("message.count", 0, false).Like Datafields, Statistics should only be created in the main body of the script such that they are created during Protocol layer instantiation. The first parameter relates to the name by which it can be referenced, and the second parameter corresponds to the value it holds initially. The final parameter is used to determine whether the Statistic is resettable. We explained previously the circumstances under which collectors are triggered and how Datafields are reset when this happens. During this process Statistics that are resettable are also reset but to the initial value given in the constructor.
The difference between script_v8 and script_v8_cut stack Protocol layers
There are two distinct versions of the script decoder which can be enabled.
The script_v8 Protocol is able to read internet Protocol or binary data passed to it from a previous layer in the stack or a probe and can be used as a fully fledged system to decode data.
The script_v8_cut Protocol is identical to the script_v8 Protocol but is unable to access data passed via a probe or previous layer.
The cut version of the decoder is useful as a Datafield translator as it is still able to access and modify Datafields defined in previous layers. It may also create additional Datafields to pass on to subsequent layers or the decoder.
The next two sections of this document relate only to the full script_v8 Decoder SDK.
Accessing internet protocol data from a script
During the on_data callback, the SDK provides a buffer attribute to the passed argument which is the sole method by which to access streamed data. There are many ways to read and decode data from this buffer which are discussed in the API reference.
The buffer object handles data buffering and stores a current byte pointer that may be advanced using various buffer methods. Methods that decode data begin with "decode" and can be used to retrieve and decode data from the stream at a certain offset from the current pointer. Methods beginning with "consume" also decode data but always at the current pointer and cause the pointer to be advanced to the byte following the consumed data.
Buffer objects retain the data contained inside them between calls to on_data and so will grow infinitely huge unless they are reset or advanced over in between calls to on_data. This makes the buffer object ideal for decoding TCP/IP data in which a single message payload may be split over multiple TCP/IP packets. The following example demonstrates this:
function on_new_decoder(dec) { dec._unfinished = false}function on_data(dec) { if (dec._unfinished) { var endIdx = dec.buffer.indexOfByte(0) // carry on looking for the "end of message marker which is the byte 0" if (endIdx == dec.buffer.size()) { // the end is still not found, keep growing the buffer until it is. } else { got_full_message(dec, endIdx) // the buffer now contains the full message dec._unfinished = false } } else { var beginIndex = dec.buffer.indexOfByte(1) if (beginIndex == dec.buffer.size()) { // the buffer containes no "message begin marker" (byte 1) so reset the buffer and look // again in the next packet dec.buffer.reset() } else { dec.buffer.advance(beginIndex) dec._unfinished = true on_data(dec) // now look for the end of the message } }}The methods used in this example are intended to be self explanatory but can be looked up in the API reference if further information is required.
dec.nextDecoder may only be called during an on_data callback.
Passing data to a decoder from the next Protocol in a stack
The examples above use dec.nextDecoder with zero arguments in order to trigger the corresponding decoder in the next Protocol layer to run. If the next decoder is also an SDK Decoder script, then it will be passed a buffer object with a size of 0.
It is also possible to pass arbitrary data to a subsequent decoder using a JavaScript string:
function on_data() { dec.nextDecoder("MARKET=3")}Usually, instead of passing fresh data, we choose to pass to the next layer a subsection of the current buffer object. This is the most common scenario whereby chained decoders each decode an outer protocol and then pass the nested protocol to the following layer. The Decoder SDK provides a simple and efficient way to support this scenario:
function on_data() { if (buffer.size() == 11) { // if the buffer contains "hello world" then "world" would be passed to the next layer. dec.nextDecoder(6, 5) } else { // This is equivalent to "dec.nextDecoder(0, 5)". If the buffer contained "hello me" then // "hello" would be passed to the next layer. dec.nextDecoder(5) }}The on_missed_data callback
This method is only called on a script if it is part of the first Protocol layer in a stack and is used to signal to the script decoder that some data was dropped by a probe. This happens in the rare circumstance that the packet decoding hardware or system resources prevent a full data decode. This method is passed the decoder object and the length in bytes of the missing data.
Full Example Script
A fully functional and well-commented decoder script can be found here.
Advanced Information
Running helper scripts using vu8.run
vu8.run executes the JavaScript script passed in the first argument. This is semantically equivalent to pasting the contents of the required script into a script at the point vu8.run is called.
vu8.run("./common/helper.js")If a relative directory path is used, then the path is looked up with respect to the directory containing the script that calls vu8.run. Whilst pasting can be used instead, this mechanism allows JavaScript code to be shared between many script decoders.
A note on threads
The v8 JavaScript virtual machine is currently single threaded. The Script Decoder SDK uses a locking system to ensure that the JavaScript virtual machine may only be used by a single thread at any point in time.
It is possible to execute multiple scripts in parallel by running each Script Protocol SDK Protocol layer from a different Packet Multiplexer.
A note on the dec.buffer object performance
A dec.buffer object allocates memory in chunks and only frees memory back to the system when a whole chunk has been consumed. This means it is efficient to call "advance" on a buffer object without concerns about performance issues. It is not possible to perform the misnomer of "advancing backwards".