Although the API calls are all standalone, you can use the results of one call to inform the next. For example, when performing a timeseries query for an aggregator, you can list the available aggregators by name and select the required id. We’ll use this approach to build our Timeseries query, as follows:
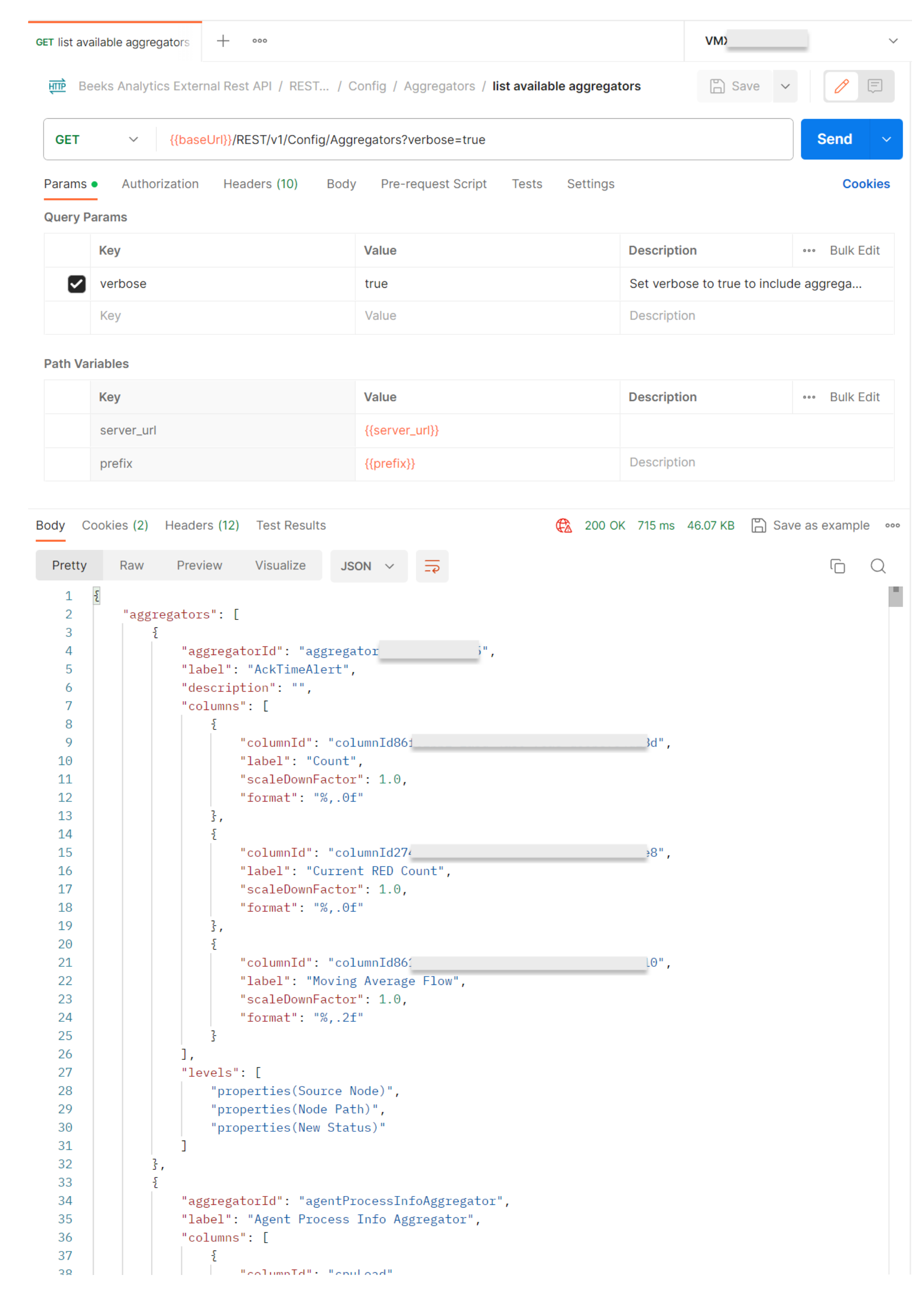
Step 1. Config: GET Aggregators
See {swagger_link_to_latest_version}/aggregators/listAggregators for a full description of this query.
This lists the available Aggregators by name.
Enable the verbose key to include Aggregator configuration details, which will allow us to get their Aggregator IDs.
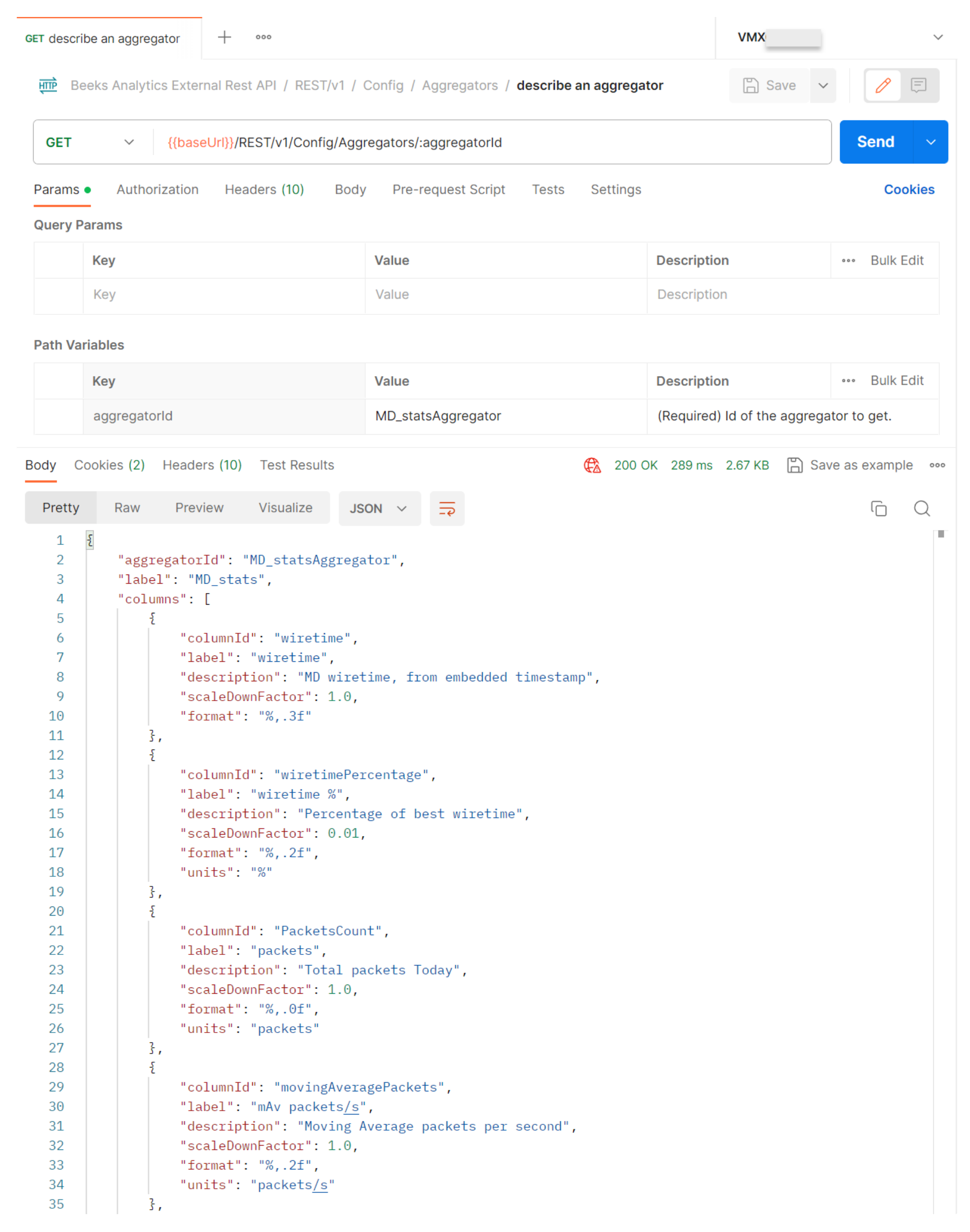
Step 2. Config: GET Aggregators/{aggregatorID}
See {swagger_link_to_latest_version}/config/getAggregator for a full description of this query.
This returns a description of a specific Aggregator.
Set aggregatorId to an Aggregator ID that was returned in the previous query.
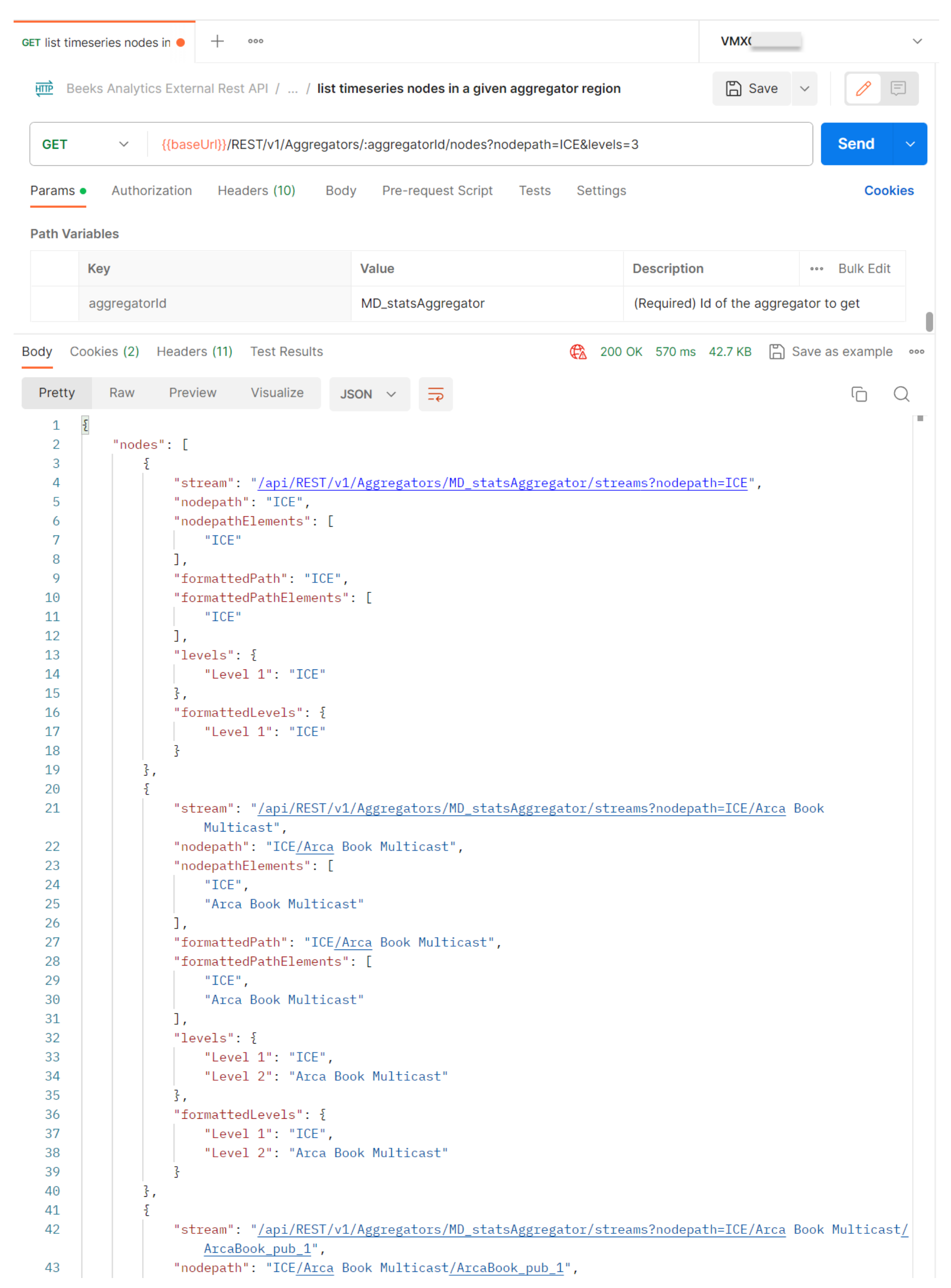
Step 3. GET Aggregators/{aggregatorId}/nodes
See {swagger_link_to_latest_version}/aggregators/getTimeseriesNodes for a full description of this query.
This returns all the nodepaths that are available a specific Aggregator.
Set aggregatorId to the Aggregator ID that you used the previous query.
Set nodepath to the region node you're interested in.
Set level to the number of levels to return, e.g. 3.
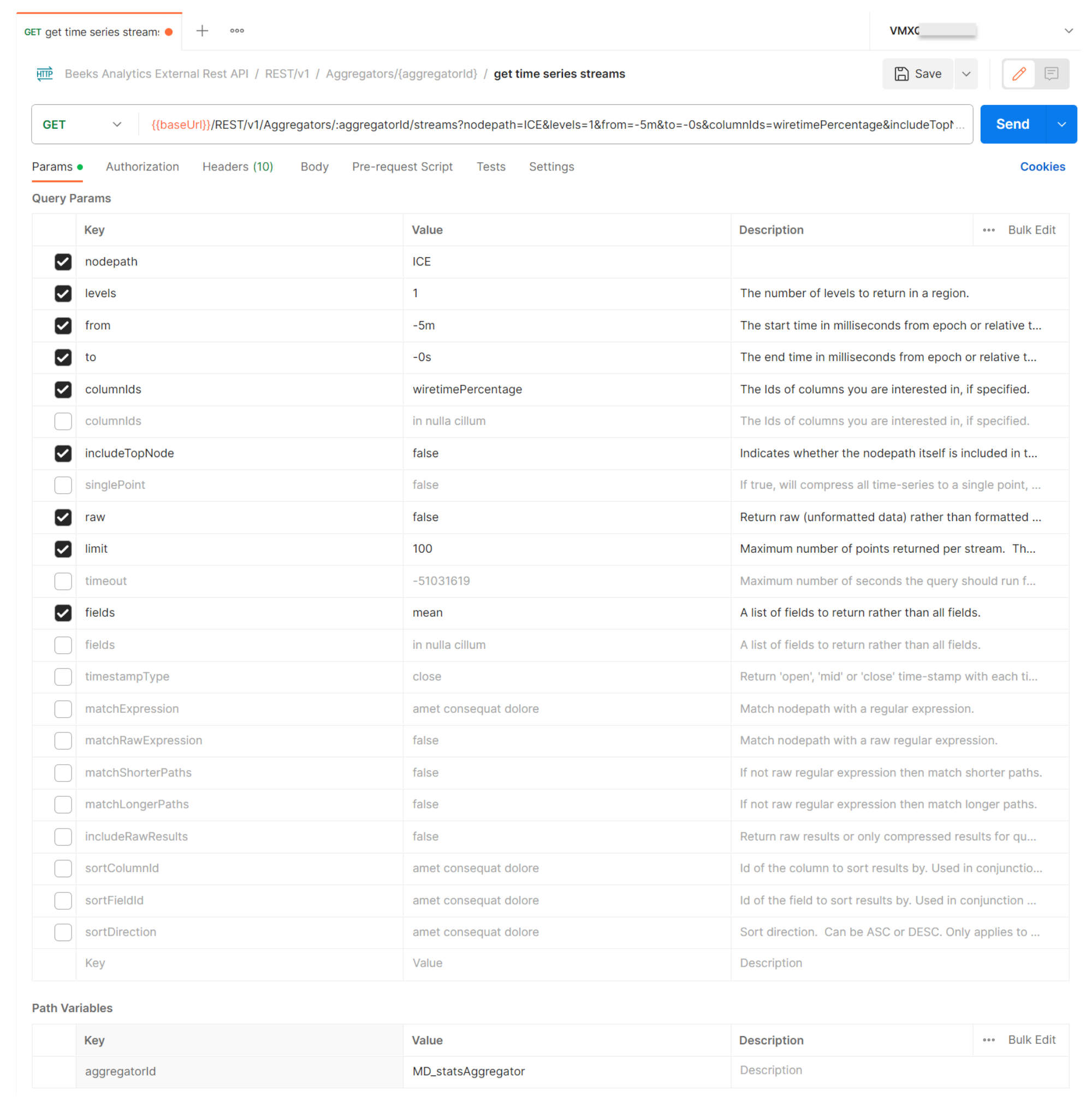
Step 4. GET Aggregators/{aggregatorId}/streams
See {swagger_link_to_latest_version}/aggregators/getTimeseriesStreams for a full description of this query.
This retrieves the Timeseries streams for an Aggregator. Using all the information you have retrieved in the previous queries, you can now build a query to retrieve the Timeseries data you are interested in.
Set aggregatorId to the Aggregator ID that you used the previous query.
Set nodepath to the region node you're interested in.
Set level to the number of levels to return, e.g. 3.
Set from to the start time in milliseconds from epoch or relative to now, e.g. -5m.
Set to to the end time in milliseconds from epoch or relative to now, e.g. -0s.
Set columnIds to the IDs of the column you're interested in, e.g. wiretimePercentage.
Set IncludeTopNode to false if you don’t want to include the nodepath itself.
Set raw to false to return formatted data.
Set limit to the maximum number of points returned per stream, e.g. 90.
Set fields to return a subset of the fields instead of all fields (array[string]).
Example results:
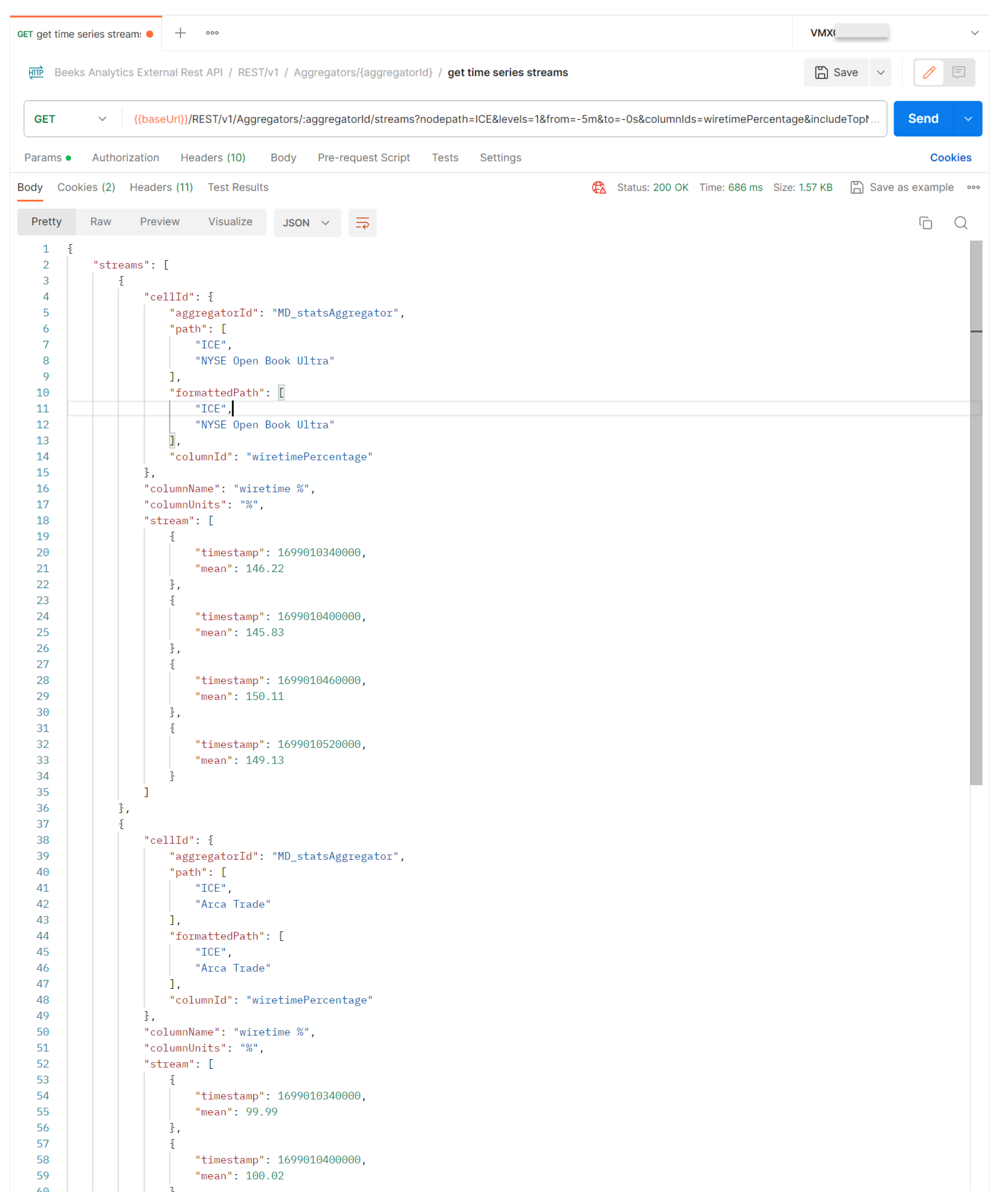
In the results of our final Timeseries query, each cell has a stream of its own with a timestamp and value. Each cell records the open, close, high, low, mean, time weighted mean, difference, % difference, and range value for each period, which were included using the field parameter.
If required, you can use these 9 values to enable dynamic quantization of a timeseries, which can be utilised for a single point - e.g. the low value for any period of time - by specifying the single point flag as TRUE.