Beeks supports many output formats for its CDF. However, our recommendation is to use Kafka data transport with JSON message encoding. The benefit of this approach is that you can use configuration/DevOps tooling to configure it, which is accessible to both developer and non-developer users. We describe the other supported output mechanisms here.
Apache Kafka is a subscription system in which Producers publish messages in topics, to which Consumers then subscribe and listen via a Consumer API. In between the Producers and Consumers are storage facilities called Brokers. Kafka enforces guaranteed messaging by requiring the Consumer to acknowledge every message.
Kafka enables you to simplify high-volume data capture but also future-proof your data pipeline. This open, robust approach eliminates the scaling bottlenecks and lock-in risks tied to legacy appliance-centric architectures, enabling you to meet the exacting demands of modern trading, compliance, and AI/ML initiatives.
Native Kafka Support for Enterprise Data Engineering
A key advantage of the Beeks Core Data Feed (CDF) streaming interface lies in its native integration with Apache Kafka. Rather than being constrained by proprietary streaming protocols or appliance-specific connectors, the CDF can seamlessly publish analytics events and decoded message flows into a standard Kafka infrastructure. This approach offers several benefits for large-scale capital markets environments:
Massive Scalability and Throughput
Kafka’s partition-based architecture enables near-linear horizontal scaling. You can add brokers to handle higher message rates, ensuring consistent low-latency delivery even as data volumes surge. This is relevant, for example, to exchanges dealing with tens of millions of messages per second—or for firms pushing real-time analytics into downstream systems without buffering or lag.Enterprise-Grade Reliability and Durability
Built-in replication and fault tolerance mean that even if individual brokers fail, your data stream remains intact and highly available. This resilience is key in financial services, where lost or partial data can have regulatory and operational implications.Open Ecosystem for Data Engineering
With Kafka as the backbone, Beeks Analytics users can integrate with a vast range of data engineering and analytics tools—such as Apache Spark, Flink, or traditional ETL pipelines. Because Kafka is already entrenched in many enterprise IT stacks, it’s straightforward to plug the Core Data Feed into existing data lakes, BI dashboards, or real-time analytics frameworks. There’s no need to rely on proprietary interfaces that limit interoperability or require specialized connectors.Supports AI/ML Initiatives
AI and machine learning workflows thrive on continuous streams of rich, high-volume data. By leveraging Kafka’s scalable publish/subscribe model, you can feed wire-level messages, order events, or latency metrics directly into ML pipelines. Data scientists and quant developers gain immediate access to high-fidelity data, fueling iterative model training and real-time inference. This native Kafka approach helps your organization keep pace with the data-hungry needs of modern AI strategies—without the bottlenecks often seen in closed, appliance-based solutions.Lower Operational Overhead
Adopting Kafka for streaming data means you can rely on well-established, widely documented best practices for deployment, monitoring, and maintenance—rather than juggling multiple vendor-specific or limited streaming tools. The open-source nature of Kafka also means you avoid extra licensing costs tied to ingestion, scaling, or replication.
Native Kafka support is more than just another interface on the Beeks platform; it is a strategic enabler that aligns with modern data engineering principles and AI-driven business priorities. By integrating the Beeks Core Data Feed directly with Kafka, you gain a flexible, robust, and future-proof mechanism for transporting mission-critical network and trading data into every corner of your enterprise ecosystem—unlocking insights faster and at greater scale.
Topics
The topics published by the CDF streaming interface are detailed at Output formats of the Core Data Feed streaming interface.
Data format
The CDF outputs to Kafka in JSON.
Producer
In Beeks Analytics, the Producer is the CDF, which takes the following data streams:
CDF-M
Data stream from VMX-Capture.CDF-T
Data stream from VMX-Capture.CDF-I
Data stream, either from VMX-Analysis or in some circumstances (usually higher volume configurations) from VMX-Capture.
Consumer
Ready-to-use Kafka connectors are widely available and you can build your own using Kafka’s Consumer API. The examples in this document use Telegraf as a Consumer to write messages to an InfluxDB database.
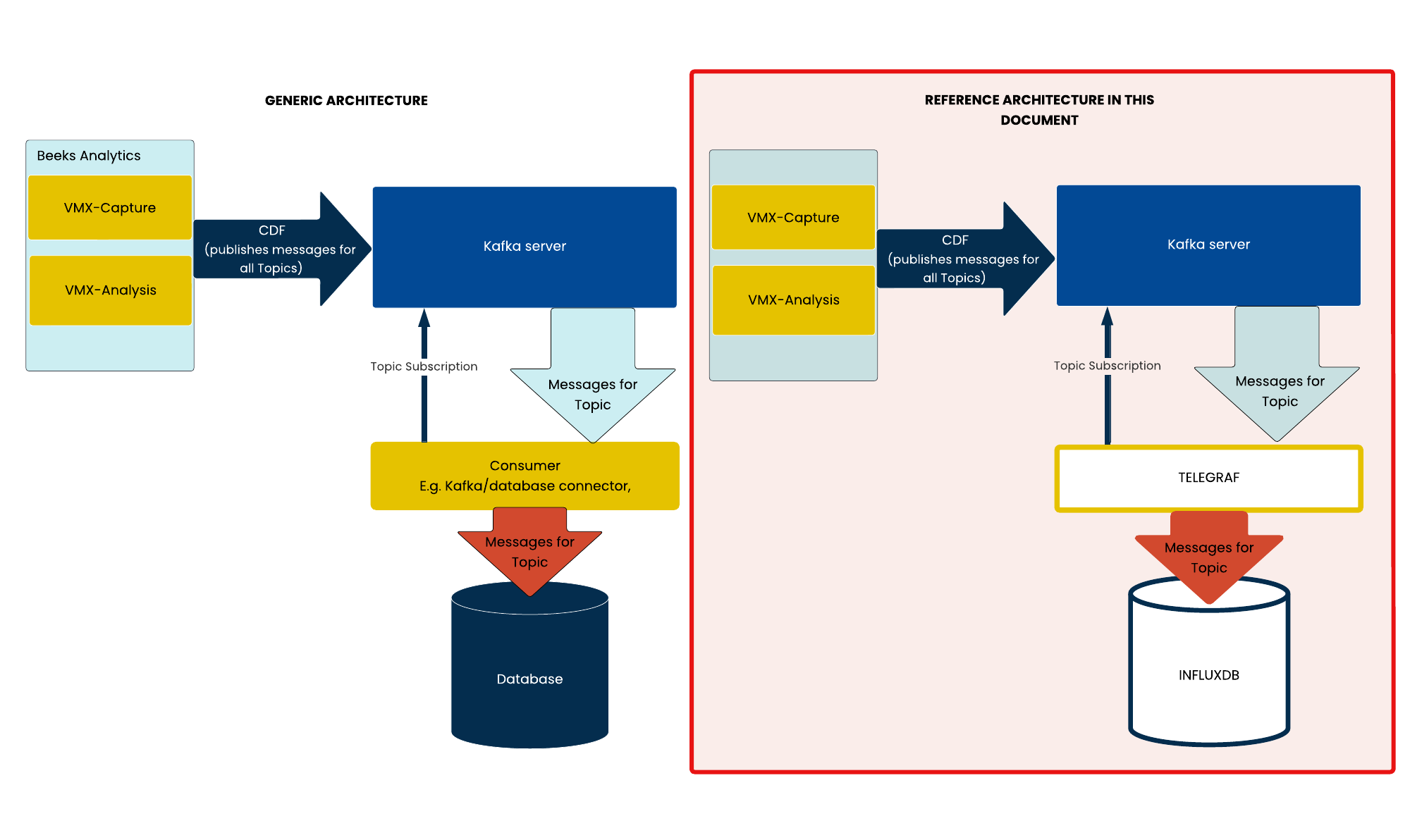
Telegraf is an agent for collecting, processing, and aggregating data. Telegraf has a Kafka Input Plugin that enables it to read data from Kafka.
InfluxDB is a time-series database that can store the data collected by the Consumer.